Final Draft 2004-JAN-29
This version:
http://www.yaml.org/spec/history/2004-01-29/
Latest version:
http://www.yaml.org/spec/
Copyright © 2001-2004 Oren Ben-Kiki, Clark Evans, Brian Ingerson
Status of this Document
This is an intermediate working draft and is being actively revised. Hopefully the next draft will be a release canidate.
We wish to thank implementers who have tirelessly tracked earlier versions of this specification, and our fabulous user community whose feedback has both validated and clarified our direction.
Abstract
YAML™ (rhymes with “camel”) is a human friendly, cross language, unicode based data serialization language designed around the common native structures of agile programming languages. It is broadly useful for programming needs ranging from configuration files to Internet messaging to object persistence to data auditing. Together with the Unicode standard for characters, this specification provides all the information necessary to understand YAML Version 1.0 and to construct programs that process YAML information.
Table of Contents
"YAML Ain't Markup Language" (abbreviated YAML) is a data serialization language designed to be human friendly and work well with modern programming languages for common everyday tasks. This specification is both an introduction to the YAML language and the concepts supporting it; and also a complete reference of the information needed to develop applications for processing YAML.
Open, interoperable and readily understandable tools have advanced computing immensely. YAML was designed from the start to be useful and friendly to the people working with data. It uses printable unicode characters, some of which provide structural information and the rest representing the data itself. YAML achieves a unique cleanness by minimizing the amount of structural characters, and allowing the data to show itself in a natural and meaningful way. For example, indentation is used for structure, colons separate pairs, and dashes are used for bulleted lists.
There are myriad flavors of data structures, but they can all be adequately represented with three basic primitives: mappings (hashes/dictionaries), sequences (arrays/lists) and scalars (strings/numbers). YAML leverages these primitives and adds a simple typing system and aliasing mechanism to form a complete language for encoding any data structure. While most programming languages can use YAML for data serialization, YAML excels in those languages that are fundamentally built around the three basic primitives. These include the new wave of agile languages such as Perl, Python, PHP, Ruby and Javascript.
There are hundreds of different languages for programming, but only a handful of languages for storing and transferring data. Even though its potential is virtually boundless, YAML was specifically created to work well for common use cases such as: configuration files, log files, interprocess messaging, cross-langauge data sharing, object persistence and debugging of complex data structures. When data is well organized and easy to understand, programming becomes a simpler task.
The design goals for YAML are:
- YAML documents are easily readable by humans.
- YAML uses the native data structures of agile languages.
- YAML data is portable between programming languages.
- YAML has a consistent model to support generic tools.
- YAML enables stream-based processing.
- YAML is expressive and extensible.
- YAML is easy to implement and use.
YAML's initial direction was set by the data serialization and markup language discussions among SML-DEV members. Later on it directly incorporated experience from Brian Ingerson's Perl module Data::Denter. Since then YAML has matured through ideas and support from its user community.
YAML integrates and builds upon concepts described by C, Java, Perl, Python, Ruby, RFC0822 (MAIL), RFC1866 (HTML), RFC2045 (MIME), RFC2396 (URI), XML, SAX and SOAP.
The syntax of YAML was motivated by Internet Mail (RFC0822) and remains partially compatible with that standard. Further, YAML borrows the idea of having multiple documents from MIME (RFC2045). YAML's top-level production is a stream of independent documents; ideal for message-based distributed processing systems.
YAML's indentation based block scoping is similar to Python's (without the ambiguities caused by tabs). Indented blocks facilitate easy inspection of a document's structure. YAML's literal scalar leverages this by enabling formatted text to be cleanly mixed within an indented structure without troublesome escaping.
YAML's double quoted scalar uses familar C-style escape sequences. This enables ASCII representation of non-printable or 8-bit (ISO 8859-1) characters such as “\x3B”. 16-bit Unicode and 32-bit (ISO/IEC 10646) characters are supported with escape sequences such as “\u003B” and “\U0000003B”.
Motivated by HTML's end-of-line normalization, YAML's folded scalar employs an intuitive method of handling white space. In YAML, single line breaks may be folded into a single space, while empty lines represent line break characters. This technique allows for paragraphs to be word-wrapped without affecting the canonical form of the content.
YAML's core type system is based on the requirements of Perl, Python and Ruby. YAML directly supports both collection (hash, array) values and scalar (string) values. Support for common types enables programmers to use their language's native data constructs for YAML manipulation, instead of requiring a special document object model (DOM).
Like XML's SOAP, YAML supports serializing native graph structures through a rich alias mechanism. Also like SOAP, YAML provides for application-defined types. This allows YAML to encode rich data structures required for modern distributed computing. YAML provides unique global type names using a namespace mechanism inspired by Java's DNS based package naming convention and XML's URI based namespaces.
YAML was designed to have an incremental interface that includes both a pull-style input stream and a push-style (SAX-like) output stream interfaces. Together this enables YAML to support the processing of large documents, such as a transaction log, or continuous streams, such as a feed from a production machine.
Newcomers to YAML often search for its correlation to the eXtensible Markup Language (XML). While the two languages may actually compete in several application domains, there is no direct correlation between them.
YAML is primarily a data serialization language. XML was designed to be backwards compatible with the Standard Generalized Markup Language (SGML) and thus had many design constraints placed on it that YAML does not share. Inheriting SGML's legacy, XML is designed to support structured documents, where YAML is more closely targeted at messaging and native data structures. Where XML is a pioneer in many domains, YAML is the result of lessons learned from XML and other technologies.
It should be mentioned that there are ongoing efforts to define standard XML/YAML mappings. This generally requires that a subset of each language be used. For more information on using both XML and YAML, please visit https://yaml.org/xml/.
This specification uses key words in accordance with RFC2119 to indicate requirement level. In particular, the following words are used to describe the actions of a YAML processor:
- may
- This word, or the adjective “optional”, mean that conformant YAML processors are permitted, but need not behave as described.
- should
- This word, or the adjective “recommended”, mean that there could be reasons for a YAML processor to deviate from the behavior described, but that such deviation could hurt interoperability and should therefore be advertised with appropriate notice.
- must
- This word, or the term “required” or “shall”, mean that the behavior described is an absolute requirement of the specification.
This section provides a quick glimpse into the expressive power of YAML. It is not expected that the first-time reader grok all of the examples. Rather, these selections are used as motivation for the remainder of the specification.
YAML's block collections use indentation for scope and begin each member on its own line. Block sequences indicate each member with a dash (“-”). Block mappings use a colon to mark each (key: value) pair.
YAML also has in-line flow styles for compact notation. The flow sequence is written as a comma separated list within square brackets. In a similar manner, the flow mapping uses curley braces. In YAML, the space after the “-” and “:” and “:” is mandatory.
YAML uses three dashes (“---”) to separate documents within a stream. Comment lines begin with the pound sign (“#”). Three dots (“...”) indicate the end of a document without starting a new one, for use in communication channels.
Repeated nodes are first marked with the ampersand (“&”) and then referenced with an asterisk (“*”) thereafter.
The question mark indicates a complex key. Within a block sequence, mapping pairs can start immediately following the dash.
Scalar values can be written in block form using a literal style (“|”) where all new lines count. Or they can be written with the folded style (“>”) for content that can be word wrapped. In the folded style, newlines are treated as a space unless they are part of a blank or indented line.
YAML's flow scalars include the plain style (most examples thus far) and quoted styles. The double quoted style provides escape sequences. Single quoted style is useful when escaping is not needed. All flow scalars can span multiple lines; intermediate whitespace is trimmed to a single space.
In YAML, plain (unquoted) scalars are given an implicit type depending on the application. The examples in this specification use types from YAML's tag repository, which includes types like integers, floating point values, timestamps, null, boolean, and string values.
Explicit typing is denoted with a tag using the bang (“!”) symbol. Application tags should include a domain name and may use the caret (“^”) to abbreviate subsequent tags.
Below are two full-length examples of YAML. On the left is a sample invoice; on the right is a sample log file.
YAML is both a text format and a method for representing native language data structures in this format. This specification defines two concepts: a class of data objects called YAML representations, and a syntax for encoding YAML representations as a series of characters, called a YAML stream. A YAML processor is a tool for converting information between these complementary views. It is assumed that a YAML processor does its work on behalf of another module, called an application. This chapter describes the information structures a processor must provide to or obtain from the application.
YAML information is used in two ways: for machine processing, and for human consumption. The challange of reconciling these two perspectives is best done in three distinct translation stages: representation, serialization, and presentation. Representation addresses how YAML views native language data structures to achieve portability between programming environments. Serialization concerns itself with turning a YAML representation into a serial form, that is, a form with sequential access constraints. Presentation deals with the formatting of a YAML serialization as a stream of characters, in a manner friendly to humans.

A processor need not expose the serialization or representation stages. It may translate directly between native objects and a character stream and (“dump” and “load” in the diagram above). However, such a direct translation should take place so that the native objects are constructed only from information available in the representation.
This section details the processes shown in the diagram above.
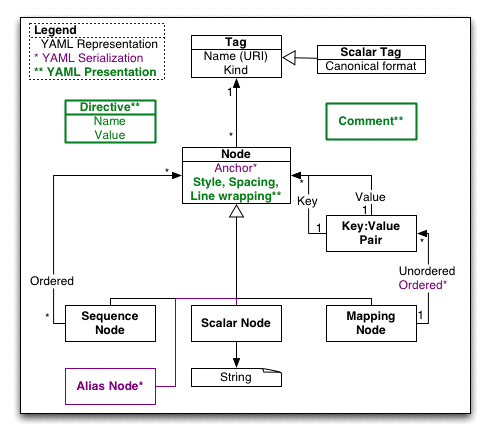
YAML representations model the data constructs from agile programming languages, such as Perl, Python, or Ruby. YAML representations view native language data objects in a generic manner, allowing data to be portable between various programming languages and implementations. Strings, arrays, hashes, and other user-defined types are supported. This specification formalizes what it means to be a YAML representatation and suggests how native language objects can be viewed as a YAML representation.
YAML representations are constructed with three primitives: the sequence, the mapping and the scalar. By sequence we mean an ordered collection, by mapping we mean an unordered association of unique keys to values, and by scalar we mean any object with opaque structure yet expressable as a series of unicode characters. When used generatively, these primitives construct directed graph structures. These primitives were chosen beacuse they are both powerful and familiar: the sequence corresponds to a Perl array and a Python list, the mapping corresponds to a Perl hashtable and a Python dictionary. The scalar represents strings, integers, dates and other atomic data types.
YAML represents any native language data object as one of these three primitives, together with a type specifier called a tag. Type specifiers are either global, using a syntax based on the domain name and registration date, or private in scope. For example, an integer is represented in YAML with a scalar plus a globally scoped tag:yaml.org,2002/int tag. Similarly, an invoice object, particular to a given organization, could be represented as a mapping together with a tag:private.yaml.org,2002:invoice tag. This simple model, based on the sequence and mapping and scalar together with a type specifier, can represent any data structure independent of programming language.
For sequential access mediums, such as an event callback API, a YAML representation must be serialized to an ordered tree. Serialization is necessary since nodes in a YAML representation may be referenced more than once (more than one incoming arrow) and since mapping keys are unordered. Serialization is accomplished by imposing an ordering on mapping keys and by replacing the second and subsequent references to a given node with place holders called aliases. The result of this process, the YAML serialization tree, can then be traversed to produce a series of event calls for one-pass processing of YAML data.
YAML character streams (or documents) encode YAML representations into a series of characters. Some of the characters in a YAML stream represent the content of the source information, while other characters are used for presentation style. Not only must YAML character streams store YAML representations, they must do so in a manner which is human friendly.
To address human presentation, the YAML syntax has a rich set of stylistic options which go far beyond the needs of data serialization. YAML has two approaches for expressing a node's nesting, one that uses indentation to designate depth in the serialization tree and another which uses begin and end delimiters. Depending upon escaping and how line breaks should be treated, YAML scalars may be written with many different styles. YAML syntax also has a comment mechanism for annotations othogonal to the “content” of a YAML representation. These presentation level details provide sufficient variety of expression.
In a similar manner, for human readable text, it is frequently desirable to omit data typing information which is often obvious to the human reader and not needed. This is especially true if the information is created by hand, expecting humans to bother with data typing detail is optimistic. Implicit type information may be restored using a data schema or similar mechanisms.
Parsing is the inverse process of presentation, it takes a stream of characters and produces a series of events.
Composing takes a series of events and produces a node graph representation. See completeness for more detail on the constraints composition must follow. When composing, one must deal with broken aliases and anchors, and other things of this sort.
This section has the formal details of the results of the processes.

To maximize data portability between programming languages and implementations, users of YAML should be mindful of the distinction between serialization or presentation properties and those which are part of the YAML representation. While imposing a order on mapping keys is necessary for flattening YAML representations to a sequential access medium, the specific ordering of a mapping should not be used to convey application level information. In a similar manner, while indentation technique or the specific scalar style is needed for character level human presentation, this syntax detail is not part of a YAML serialization nor a YAML representation. By carefully separating properties needed for serialization and presentation, YAML representations of native language information will be consistent and portable between various programming environments.
In YAML's view, native data is represented as a directed graph of tagged nodes. Nodes that are defined in terms of other nodes are collections and nodes that are defined independent of any other nodes are scalars. YAML supports two kinds of collection nodes, sequence and mappings. Mapping nodes are somewhat tricky beacuse its keys are considered to be unordered and unique.

A YAML representation is a rooted, connected, directed graph. By “directed graph” we mean a set of nodes and arrows, where arrows connect one node to another ( a formal definition ). Note that the YAML graph may include cycles, and a node may have more than one incoming arrow.
YAML nodes have a tag and can be of one of three kinds: scalar, sequence, or mapping. The node's tag serves to restrict the set of possible values which the node can have.
- scalar
-
A scalar is a series of zero or more Unicode characters. YAML places no restriction on the length or content of the series.
- sequence
-
A sequence is a series of zero or more nodes. In particular, a sequence may contain the same node more than once or it could even contain itself (directly or indirectly).
- mapping
-
A mapping is an unordered set of key/value node pairs, with the restriction that each of the keys is unique. This restriction has non-trivial implications detailed below. YAML places no further restrictions on the nodes. In particular, keys may be arbitrary nodes, the same node may be used as a value in several pairs, and a mapping could even contain itself as a key or a value (directly or indirectly).
When appropriate, it is convient to consider sequences and mappings together, as a collection. In this view, sequences are treated as mappings with integer keys starting at zero. Having a unified collections view for sequences and mappings is helpful for both constructing practical YAML tools and APIs and for theoretical analysis.
YAML allows several representations to be encoded to the same character stream. Representations appearing in the same character stream are independent. That is, a given node may not appear in more than one representation graph.
YAML represents type information of native objects with a simple identifier, called a tag. These identifiers are URIs, using a subset of the “tag” URI scheme. YAML tags use only the domain based form, tag:domain,date:identifier, for example, tag:yaml.org,2002:str. YAML presentations provide several mechanisms to make this less verbose. Tags may be minted by those who own the domain at the specified date. The day must be omitted if it is the 1st of the month, and the month and day must be omitted for January 1st. The year is never omitted. Thus, each YAML tag has a single globally unique representation. More information on this URI scheme can be found at http://www.taguri.org (mirror).
YAML tags can be either globally unique, or private to a single representation graph. Private tags start with tag:private.yaml.org,2002:. Clearly private tags are not globally unique, since the domain name and the date are fixed.
YAML does not mandate any special relationship between different tags that begin with the same substring. Tags ending URI fragments (containing “#”) are no exception. Tags that share the same base URI but differ in their fragment part are considered to be different, independent tags. By convention, fragments are used to identify different “versions” of a tag, while “/” is used to define nested tag “namespace” hierarchies. However, this is merely a convention, and each tag may employ its own rules. For example, tag:perl.yaml.org,2002: tags use “::” to express namespace hierarchies, tag:java.yaml.org,2002: tags use “.”, etc.
YAML tags are used to associate meta information with each node. In particular, each tag is required to specify a the kind (scalar, sequence, or mapping) it applies to. Scalar tags must also provide mechanism for converting values to a canonical form for supporting equality testing. Furthermore, a tag may provide additional information such as the set of allowed values for validation, a mechanism for implicit typing, or any other data that is applicable to all of the tag's nodes.
Since YAML mappings require key uniqueness, representations must include a mechanism for testing the equality of nodes. This is non-trivial since YAML presentations allow various ways to write a given scalar. For example, the integer ten can be written as 10 or 0xA (hex). If both forms are used as a key in the same mapping, only a YAML processor which “knows” about integer tags and their presentation formats would correctly flag the duplicate key as an error.
- canonical form
-
YAML supports the need for scalar equality by requiring that every scalar tag have a mechanism to produce a canonical form of its scalars. By canonical form, we mean a Unicode character string which represents the scalar's content and can be used for equality testing. While this requirement is stronger than a well defined equality operator, it has other uses, such as the production of digital signatures.
- equality
-
Two nodes must have the same tag and value to be equal. Since each tag applies to exactly one kind, this implies that the two nodes must have the same kind to be equal. Two scalar nodes are equal only when their canonical values are character-by-character equivalent. Equality of collections is defined recursively. Two sequences are equal only when they have the same length and each node in one sequence is equal to the corresponding node in the other sequence. Two mappings are equal only when they have equal sets of keys, and each key in this set is associated with equal values in both mappings.
- identity
-
Node equality should not be confused with node identity. Two nodes are identical only when they represent the same native object. Typically, this corresponds to a single memory address. During serialization, equal scalar nodes may be treated as if they were identical. In contrast, the seperate identity of two distinct, but equal, collection nodes must be preserved.
To express a YAML representation using a serial API, it necessary to impose an order on mapping keys and employ alias nodes to indicate a subsequent occurence of a previously encountered node. The result of this serialization process is a tree structure, where each branch has an ordered set of children. This tree can be traversed for a serial event based API. Construction of native structures from the serial interface should not use key order or anchors for the preservation of important data.

In the representation model, keys in a mapping do not have order. To serialize a mapping, it is necessary to impose an ordering on its keys. This order should not be used when composing a representation graph from serialized events.
In every case where node order is significant, a sequence must be used. For example, an ordered mapping can be represented by a sequence of mappings, where each mapping is a single key/value pair. YAML presentations provide convient shorthand syntax for this case.
In the representation model, a node may appear in more than one context. When serializing such nodes, the first occurance of the node is serialized with an anchor and subsequent occurances are serialized as an alias which specifies the same anchor. Anchors need not be unique within a serialization. When composing a representation graph from serialized events, alias nodes refer to the most recent node in the serialization having the specified anchor.
An anchored node need not have an alias referring to it. It is therefore possible to provide an anchor for all nodes in serialization. After composing a representation graph, the anchors are discarded. Hence, anchors must not be used for encoding application data.
YAML presentations make use of styles, comments, directives and other syntactical details. Although the processor may provide this information, these features should not be used when constructing native structures.
In the syntax, each node has an additional style property, depending on its node. There are two types of styles, block and flow. Block styles use indentation to denote nesting and scope within the presentation. In contrast, flow styles rely on explicit markers to denote nesting and scope.
YAML provides several shorthand forms for collection styles, allowing for compact nesting of collections in common cases. For compact set notation, null mapping values may be omitted. For compact ordered mapping notation, a mapping with a single key:value pair may be specified directly inside a flow sequence collection. Also, simple block collections may begin in-line rather than the next line.
YAML provides a rich set of scalar style variants. Scalar block styles include the literal and folded styles; scalar flow styles include the plain, single quoted and double quoted styles. These styles offer a range of tradeoffs between expressive power and readability.
The syntax allows optional comment blocks to be interleaved with the node blocks. Comment blocks may appear before or after any node block. A comment block can't appear inside a scalar node value.
Each document may be associated with a set of directives. A directive is a key:value pair where both the key and the value are simple strings. Directives are instructions to the YAML processor, allowing for extending YAML in the future. This version of YAML defines a single directive, “YAML”. Additional directives may be added in future versions of YAML. A processor should ignore unknown directives with an appropriate warning. There is no provision for specifying private directives. This is intentional.
The “YAML” directive specifies the version of YAML the document adheres to. This specification defines version 1.0. A version 1.0 processor should accept documents with an explicit “%YAML:1.0” directive, as well as documents lacking a “YAML” directive. Documents with a directive specifying a higher minor version (e.g. “%YAML:1.1”) should be processed with an appropriate warning. Documents with a directive specifying a higher major version (e.g. “%YAML:2.0”) should be rejected with an appropriate error message.
The process of converting YAML information from a character stream presentation to a native data structure has several potential failure points. The character stream may be ill-formed, implicit tags may be unresolvable, tags may be unrecognized, the content may be invalid, and a native type may be unavailable. Each of these failures results with an incomplete conversion.
A partial representation need not specify the tag of each node, and the canonical form of scalar values need not be available. This weaker representation is useful for cases of incomplete knowledge of tags used in the document.
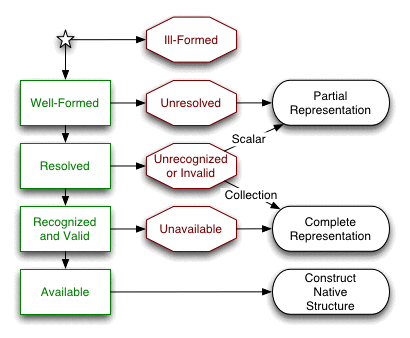
A well-formed character stream must match the productions specified in the next chapter. A YAML processor should reject ill-formed input. A processor may recover from syntax errors, but it must provide a mechanism for reporting such errors.
It is not required that all tags in a complete YAML representation be explicitly specified in the character stream presentation. In this case, these implicit tags must be resolved.
When resolving tags, a YAML processor must only rely upon representation details, with one notable exception. It may consider whether a scalar was written in the plain style when resolving the scalar's tag. Other than this exception, the processor must not rely upon presentation or serialization details. In particular, it must not consider key order, anchors, styles, spacing, indentation or comments.
The plain scalar style exception allows unquoted values to signify numbers, dates, or other typed data, while quoted values are treated as generic strings. With this exception, a processor may match plain scalars against a set of regular expressions, to provide automatic resolution of such types without an explict tag.
If a document contains unresolved nodes, the processor is unable to compose a complete representation graph. However, the processor may compose an partial representation, based on each node's kind (mapping, sequence, scalar) and allowing for unresolved tags.
To be valid, a node must have a tag which is recognized by the processor and its value must satisfy the constraints imposed by its tag. If a document contains a scalar node with an unrecognized tag or an invalid value, only a partial representation may be composed. In constrast, a processor can always compose a complete YAML representation for an unrecognized or an invalid collection, since collection equality does not depend upon the collection's data type.
In a given processing environment, there may not be an available native type corresponding to a given tag. If a node's tag is unavailable, a YAML processor will not be able to construct a native data structure for it. In this case, a complete YAML representation may still be composed, and an application may wish to use this representation directly.